
How to dynamically load CSV data into Postgres?
Learn how to use Docker, PostgreSQL, and PGAdmin to load data without having to type every column name.

As a new data professional, mastering data loading is a key skill. In this guide, we will explore how to perform this task using Docker, providing a practical example with PostgreSQL. This is not intended to be an introduction to these tools. You need to know SQL; any kind will do, I am just using PostgreSQL here. Let's dive right in!! :)

Docker
What is Docker? Docker can package and run applications or software in what they call "Containers"; so there won't be an issue of "Hey it is working in my computer but not yours." It is kind of like Virtual Machines but not really. It's more efficient, faster, and more for app-specific environments.

We can build our docker image (software) but instead will use an existing one from Docker. My main reason for using this is I do not want to download and install Postgres or PGAdmin on my laptop.
Since we need PGAdmin and Postgres, we will be using Docker Compose. It just allows us to run multiple Docker containers. Learn more about docker-compose here.
Download and Install: If you haven't already, download and install Docker Desktop from the official Docker website.
Verify Installation: Open a terminal or command prompt and run
docker --versionto verify the installation.
You might need to open Docker Desktop if you encounter an error while running docker commands. On Mac I ran
open -a Dockerin terminal but we can also just open the app.
Developing `docker-compse.yaml`
We need a code editor to create a Docker Compose file; I am using Visual Studio Code, but you can use an editor of your choice.
First, let’s create a new file called
docker-compose.yaml. Docker will automatically understand what to do with this file.Now let’s set the services we need in the
yamlfile; Postgres and PGAdmin.
services:
pgdatabase:
image: postgres:latest
environment:
- POSTGRES_USER=root
- POSTGRES_PASSWORD=root
- POSTGRES_DB=world_forest
ports:
- 5432:5432
volumes:
- ./data_postgres:/var/lib/postgresql/data:rw
- ./csv_data:/csv_data:rw
pgadmin:
image: dpage/pgadmin4
environment:
- PGADMIN_DEFAULT_EMAIL=thebad@coder.com
- PGADMIN_DEFAULT_PASSWORD=root
ports:
- 8080:80
volumes:
- ./pgadmin-data:/var/lib/pgadmin:rwWe start by defining our
services, which are 2 docker containers
Our first container is for Postgres so let's name it
pgdatabase. This will be inside the services block. (blocks work similarly to Python; not really)
Inside that, we need to define the
imageDocker needs to pull.postgres:latestwill pull the latest version of Postgres from Docker (unless you already have an image of Postgres pulled).
Next, we have
environmentto set up the credentials and database name,portsto map the ports with our local machine, andvolumesto map folder structure to our local machine so that we can persist in our work. (rwis for read/write access)
We also set up another folder structure
/csv_datathat can be used to store our csv file. :)
We do the same for PGAdmin.
SAVE the file and then go to a terminal window or command prompt or (in my case) cmd within VS Code navigate to the folder where this yaml file is and run docker-compose up -d. We probably have to wait a little bit for it to pull and build the images.
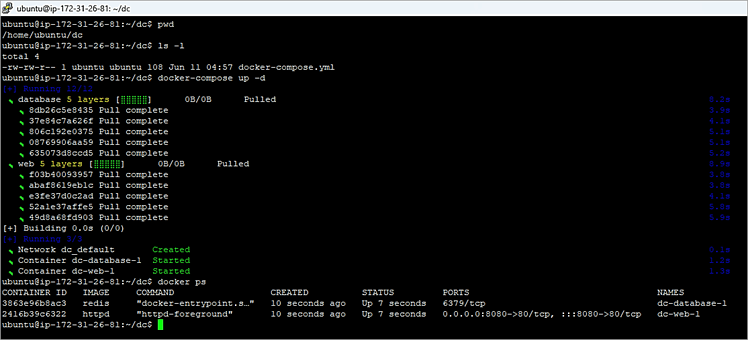
*Viola!* Well not really right?
Go to http://localhost:8080 on your browser...
Now we can *viola!* We have Postgres and are ready to use it through PGAdmin. Simply sign in using the credentials you set.
Now to add the server; we need to connect PGAdmin to the Postgres server. To add a server:
Click on Add New Server of course. Name it anything you want.
Head on over to the Connections tab and use
pgdatabaseas the service name to connect to the server.
Enter your credentials and SAVE.
SQL: Creating the Table

Now let's talk data. We will be using the World Forest data from Kaggle. First, we need to look at the dataset and create the table. As we can see the columns we need are Country Name, Country Code, and a bunch of year columns. (screenshot below)
Manually typing out all the year columns is a lot and we need to show off some SQL so let's use a script that automatically generates the column definitions based on the CSV file's header. Since we know the country columns are string type and the year columns are float, it should be fairly easy. This approach uses the unnest() function and the string_agg() function in PostgreSQL to construct the CREATE TABLE statement dynamically.
We can take the first row of the file and/or create a table in other ways that are far better than this. This is generally not a good approach but our goal here is to flex our SQL skills.
Now, I found that there are two ways to achieve this; one is using a TEMP TABLE and the other is using the pg_read_file() function.
Using TEMP TABLE Method
First, we create a temporary table where our goal is to save the first row as a TEXT. Honestly, it is better to use Excel or Python to extract only the first row of the file but I want to make it more complicated and use SQL :)
CREATE TEMP TABLE tmp_table (line TEXT);
COPY tmp_table FROM '/path/to/your/csvfile.csv' DELIMITER '*' CSV;Note: I am using `
*` as the delimiter since we want the whole first row and using `,` would defeat this purpose. `*` is something that is not there in the file so essentially I am telling it to delimit by nothing.
We use the
COPYcommand to take all the data from the CSV file and delete everything but the first row.
Use the system column in PostgreSQL
ctidto keep only the first row. This is useful as the id is based on the order of rows in which the data was inserted.
DELETE FROM tmp_table
WHERE ctid != (SELECT ctid FROM tmp_table LIMIT 1);
SELECT * FROM tmp_table;Now that we have the first row as a text, all we need to do is unnest() it and then use a CASE statement to generate our CREATE TABLE statement.
Before that, we will take advantage of
string_to_array()to break the text by `,`. This will convert the text into an array but within that same row.
Then we
unnest()the array and it is then broken down into rows.
SELECT unnest(string_to_array(line, ',')) FROM tmp_table;
--Better version
SELECT unnest(string_to_array(trim(both E'\n' from line), ',')) column_name
FROM tmp_tableA better version is using
trim()function to clean up the column names removing spaces and newlines. Doesn't really matter in our case. (screenshot)
Let's put this into a CTE (Common Table Expression) so it is more readable and develops our `CASE` statement.
;WITH colnames AS (
SELECT unnest(string_to_array(trim(both E'\n' from line), ',')) column_name
FROM tmp_table)
SELECT string_agg(
'"'||column_name||'"' || ' ' || CASE
WHEN column_name LIKE '%Country%' THEN 'VARCHAR(255)'
ELSE 'FLOAT'
END, ', '
) FROM colnames;Notice we used `""` to encapsulate `column_name` in quotes. This is because column names cannot contain space or start with digits unless they are within quotes.
We need to insert this into a variable, plug the variable into an EXECUTE statement, and execute it (duh). The actual final query looks something like this:
DO $$
DECLARE
column_definitions TEXT;
BEGIN
WITH colnames AS (
SELECT unnest(string_to_array(line, ',')) column_name
FROM tmp_table)
SELECT string_agg(
'"'||column_name||'"' || ' ' || CASE
WHEN column_name LIKE '%Country%' THEN 'VARCHAR(255)'
ELSE 'FLOAT'
END, ', '
) INTO column_definitions
FROM colnames;
EXECUTE 'CREATE TABLE world_forest(' || column_definitions || ');';
END $$;We need DO and BEGIN blocks while working with variables in PostgreSQL. Pretty straightforward forward right?

Finally, we have our table created and all that's left is to load the data into the table!
COPY world_forest FROM '/csv_data/forest_area_km.csv' WITH (FORMAT csv, HEADER);Using pg_read_file() Method
This IMO is an even worse method because we are taking advantage of this one parameter in the pg_read_file() function that will help us consume only the first row. Everything else we will be doing is the same as above.
SELECT pg_read_file('/csv_data/forest_area_km.csv', 0, 185);One of the parameters determines the number of bytes that should be read from the file. Since CSV is row-based, I was able to do some trial and error to find out the 185 bytes of space is what the header is taking.
Note that you might not have the right permissions and the need for superuser rights would be required since this function might not be accessible to all users.
Anyways our final query for this will look like this:
DO $$
DECLARE
column_definitions TEXT;
BEGIN
WITH header_line as
(SELECT pg_read_file('/csv_data/forest_area_km.csv', 0, 185))
SELECT string_agg(
'"'||column_name||'"' || ' ' || CASE
WHEN column_name LIKE '%Country%' THEN 'VARCHAR(255)'
ELSE 'INT'
END, ', '
) INTO column_definitions
FROM unnest(string_to_array(trim(both E'\n' from (SELECT * FROM header_line)), ',')) AS column_name;
EXECUTE 'CREATE TABLE world_forest(' || column_definitions || ');';
END $$;And then we simply load the CSV file into the table just created.
COPY my_table(name, age) FROM '/path/to/your/file.csv' WITH (FORMAT csv, HEADER);Finally, we have our data and are ready to do some analysis, if you like this one please show your support and maybe I can for the next part use SQL to extract various insights from this dataset.
That's it for today, if you have questions or insights from following this tutorial, feel free to reach me on LinkedIn or leave a comment below :)
Break Into Data is your launchpad into the world of data science and analytics. We provide hands-on experience, expert guidance, and a supportive community to help you thrive in the data-driven job market. Join our discord or check out our website breakintodata.io
This is an amazing write up!